
스프링을 공부하다보면 무조건 등장하는 어노테이션이다.
내가 현재 알고있는 지식은 @Controller, @Service, @Repository 모두 @Component라는 어노테이션을 포함하고 있기 때문에 컴포넌트 스캔 대상이되어 빈으로 등록된다는 것이다.
그런데, 이런 의문점이 생겼다.
모두 @Component 어노테이션을 포함하는데, 굳이 구분하는 이유가 무엇일까?
각각의 특징이 따로 있는 것일까?
모두 스프링 컨테이너가 관리하는 빈의 등록되기 위해서 위와 같은 어노테이션을 사용했다면, @Component만 쓰면 되었을텐데 왜 나누어 놓은 것일까? 그 이유가 분명히 있을 터..! 이러한 의문점에서 시작하였다.
@Controller
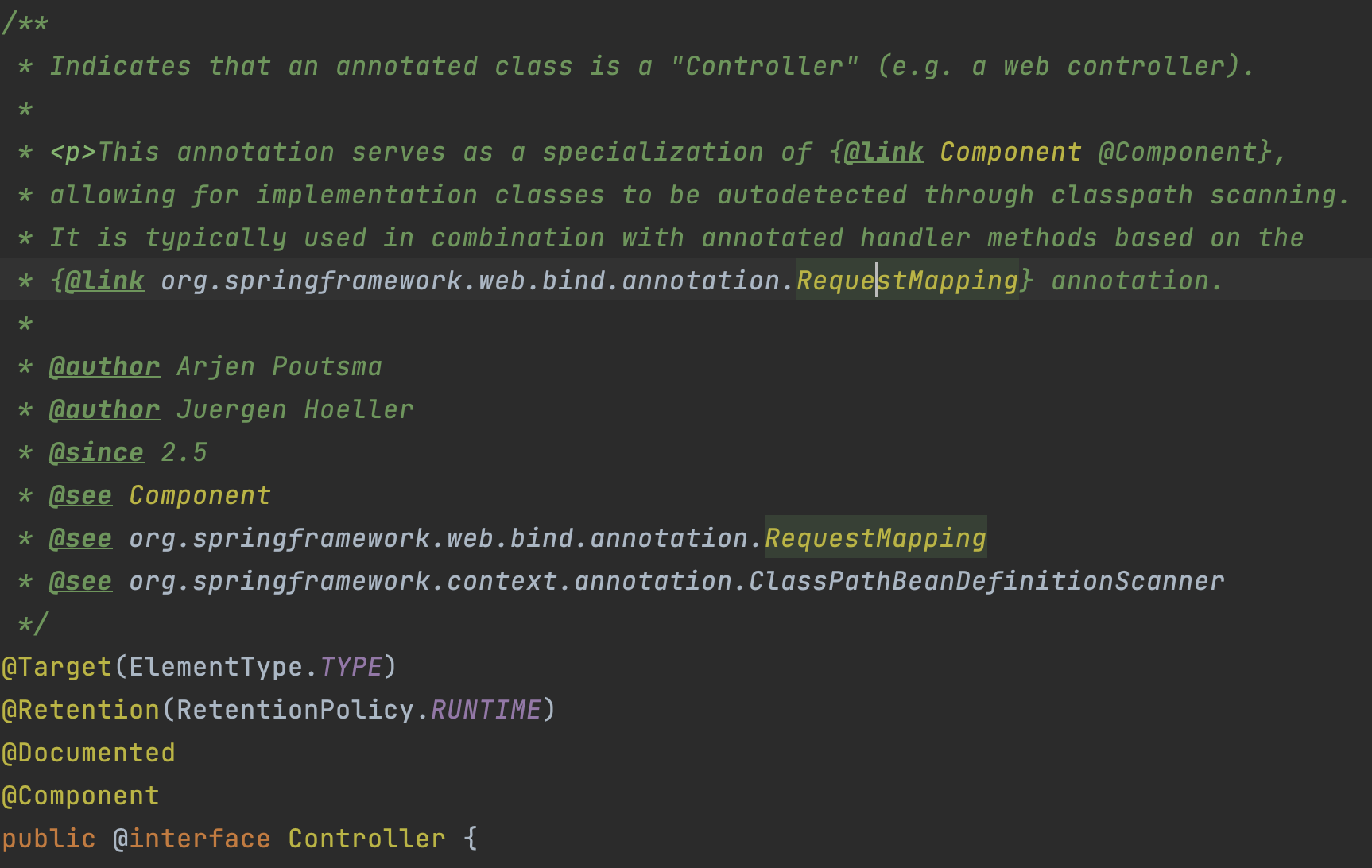
첫 번째로 Intellij안에서 @Controller 어노테이션에 들어가 봤다.
주석에 간단한 설명이 되어 있는데, @Component의 특수한 역할을 한다고 되어 있는데 특수한 역할이 뭘까..?
또한, @RequestMapping을 기반으로한 handler methods와 함께 사용된다고 나와있다... 흠..?
이것만으로는 충족이 안된다. @Component와의 근본적인 차이점을 찾아야한다.
두 번째로 Spring documents를 뒤져보았다.
공식 문서를 보다가 다음과 같은 문장을 보았다.
The basic purpose of the @Controller annotation is to act as a stereotype for the annotated class, indicating its role. The dispatcher will scan such annotated classes for mapped methods, detecting @RequestMapping annotations (see the next section).
요악해보자면 dispatcher가 @Controller 어노테이션이 달린 클래스들을 스캔하여 @RequestMapping 어노테이션이 달린 methods를 찾는다.
아마도 여기서 얘기하는 dispatcher는 내가 어렴풋이 알고 있는 dispatcherServlet을 말하는 것 같다.
내가 생각하기로는 DispatcherServlet으로 들어온 요청에 url에 맞는 method를 호출해야하는데, 그렇다면 어떠한 method들이 요청을 처리할 수 있는 method들인지 알아야한다. 이렇게 요청을 처리할 수 있는 method는 @RequestMapping 어노테이션이 달려있는 method일 것이다. 모든 곳을 뒤져볼 수는 없으니, @Controller 어노테이션이 달린 클래스 안의 method들만 detect하여 요청을 처리할 수 있는 method들을 가져오는 것 같다.
자세한 내용을 알기 위해서는 DispatcherServlet이 요청을 매핑하는 과정을 알아야할 것 같다. 너무 들어가면 한도 끝도 없으니..
일단 스프링 기술부채에 기록해둬야겠다..! ㅎㅎ
@Service
이제 알아볼 것은 @Service이다. Presentation Layer와 Persistence Layer사이에 존재하는 Layer에 붙는 어노테이션이다.
Presentation Layer에서 요청 받은 작업을 실질적으로 행하는 곳으로, 일련의 비지니스 로직을 실행한다.
위와 마찬가지로 Intellij에서 @Service에 들어가보자!
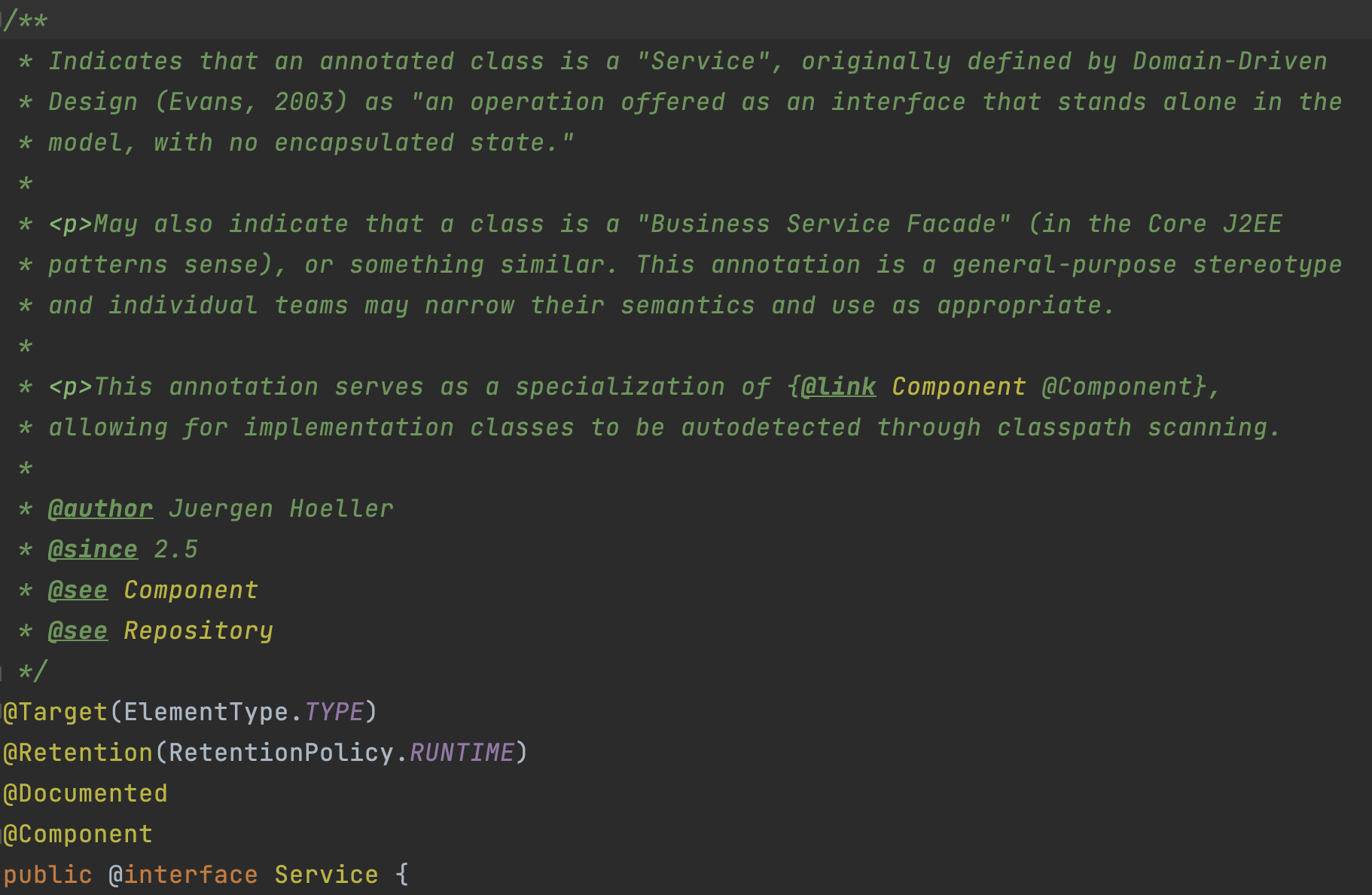
"Business Service Facade" ?? 비지니스 서비스라는 것을 알려주기 위함인가?
딱히 @Service를 붙인다고 해서 @Component와 차이점을 설명해주고 있지는 않다.
두 번째로, 공식 문서를 뒤져보자 !
It is also possible that @Repository, @Service, and @Controller may carry additional semantics in future releases of the Spring Framework. Thus, if you are choosing between using @Component or @Service for your service layer, @Service is clearly the better choice. Similarly, as stated above, @Repository is already supported as a marker for automatic exception translation in your persistence layer.
요약해보자면, 서비스 레이어에서 @Component, @Service 중 선택을 해야한다면, @Service를 선택하는게 명백히 최고의 선택이라는 것이다. 왜냐하면, 언젠가 @Service 어노테이션에 추가적인 의미, 즉 기능을 부여할 수도 있기 때문이라고 한다. 마치 @Repository가 이미 @Component와는 다르게 persistence layer에서 자동으로 예외를 변환시키는 작업을 포함하고 있는 것처럼 말이다.
생각을 정리하면, @Service 어노테이션을 붙인다고 해서 @Component와는 차이가 없지만, 미래에 추가적인 기능이 생길 수도 있으므로, 서비스 레이어서는 @Service를 붙이라는 것이다. 일리가 있는 말이군요... 기능상의 차이는 아직까지는 없다!!
@Repository
Database와 interaction을 하며 Persistence layer에 붙이는 어노테이션이다.
과연 컴포넌트스캔 대상이되어 자동으로 빈으로 등록되는 일을 제외하고 어떤 작업을 추가로 해줄까..?
아까 @Service 어노테이션을 찾아보다 힌트를 얻었다. 예외변환 작업을 해준다는데... 일단 Intellij에서 어노테이션을 까보자!
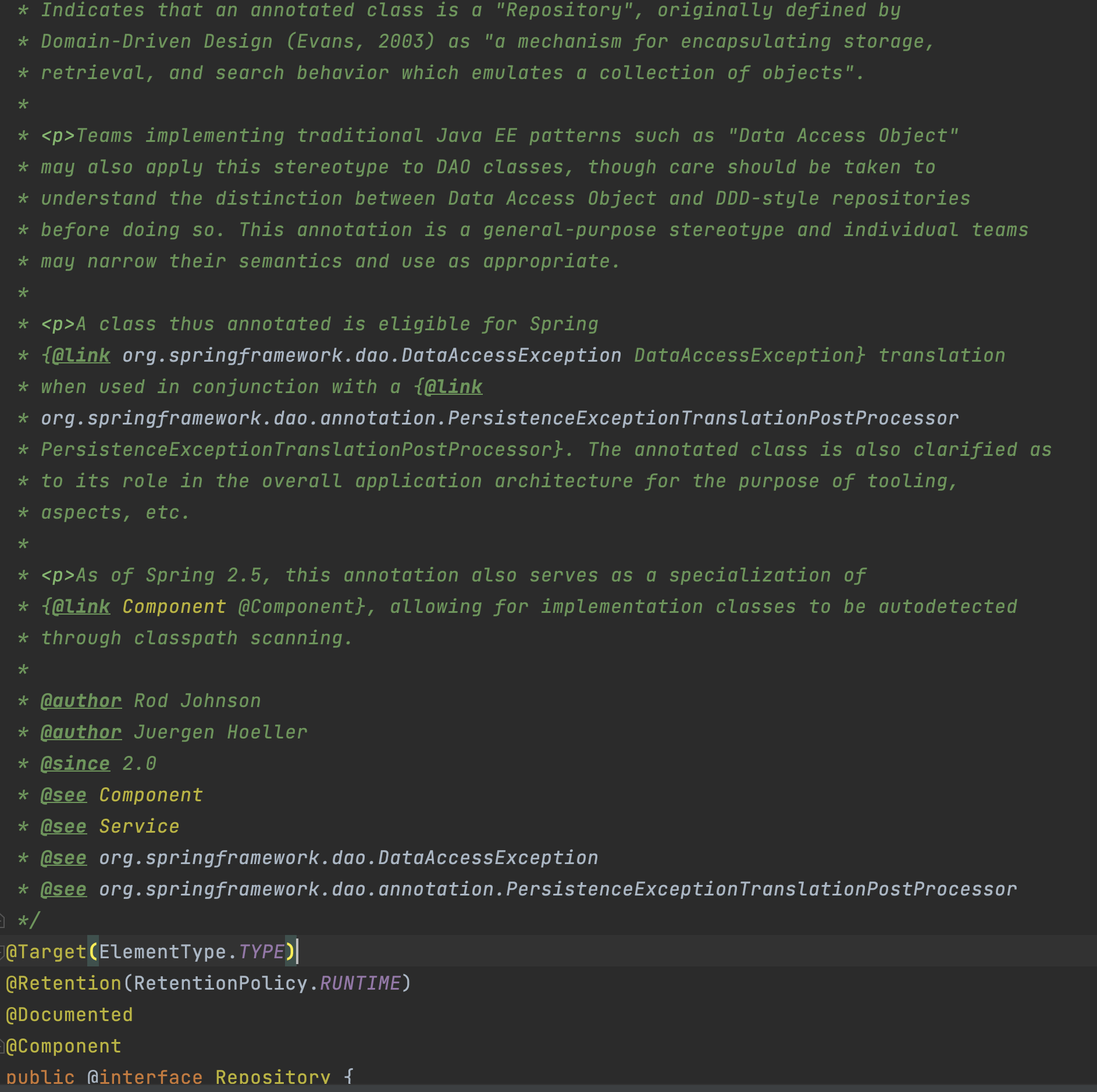
이 글과는 관련이 없지만, DAO와 DDD-style의 repository의 차이점을 이해해야 한다고 써져있다.
그러고보니, 미션을 진행할 때 DAO 클래스위에 @Repository 어노테이션을 달아줬었는데... DAO와 Repository의 차이가 뭘까?
이것도 기술부채에 추가해야겠다 !
주석을 읽어보면 결국 예외 변환을 시켜준다는 얘기인것 같다. PersistenceExceptionTranslationPostProcessor와 결합하여 Spring의 DataAccessException으로 변환해준다고 나와있다.
PersistenceExceptionTranslationPostProcessor에 대한 문서에 아래와 같이 나와있다.
Bean post-processor that automatically applies persistence exception translation to any bean marked with Spring's @Repository annotation, adding a corresponding PersistenceExceptionTranslationAdvisor to the exposed proxy (either an existing AOP proxy or a newly generated proxy that implements all of the target's interfaces).
Translates native resource exceptions to Spring's DataAccessException hierarchy.
Autodetects beans that implement the PersistenceExceptionTranslator interface, which are subsequently asked to translate candidate exceptions.
요약하자면, @Repository 어노테이션이 붙어있는 어떠한 빈이면, Bean post-processor가 예외변환을 해준다.
즉, native한 리소스 예외를 스프링이 제공하는 DataAccessException 계층 구조로 변환해준다는 것이다.
공식문서를 더 찾아보면 아래와 같은 얘기가 나온다.
Spring provides a convenient translation from technology-specific exceptions like SQLException to its own exception class hierarchy with the DataAccessException as the root exception. These exceptions wrap the original exception so there is never any risk that one might lose any information as to what might have gone wrong.
스프링은 SQLExeption과 같은 기술구체적인 예외를 자신의 예외클래스 계층구조인 DataAccessException으로의 편리한 변환을 제공한다고 한다. 이러한 예외는 원본의 예외를 감싸고 있으며, 무엇이 잘못되어서 예외가 발생한건지에 대한 어떠한 정보도 잃어버릴 위험이 없다고 한다.
그렇다면 왜 예외를 변환하는 것일까? 예외를 변환하면 이점이 무엇일까?
내 생각은 다음과 같다.
1. 특정 데이터베이스에 의존적인 예외를 wrapping하여 공통적인 예외처리를 할 수 있다.
H2 데이터베이스를 사용했을 때, JdbcSqlException이 발생할 수 있다. 이런 예외가 발생할 수 있기에 서비스 레이어에서는 try-catch구문을 사용하여 해당예외를 잡을 수 있다. 하지만, 중간에 데이터베이스가 바뀐다면 ?
JdbcSqlException은 org.h2.jdbc.JdbcSqlException인 H2 데이터베이스만의 예외이다. 그러므로 데이터베이스가 바뀐다면 서비스 레이어안의 예외를 잡는 부분 또한 영향을 받을 수 있다.
그렇기에 예외를 DataAccessException이라는 공통적인 예외로 변환시켜 던지면, 특정 데이터베이스에 의존적인 예외를 잡지 않아도 된다는 이점이 있는 것 같다. 즉, 추상화된 예외로 서비스 계층에서 잡을 수 있다!
2. 계층화된 구조로 원하는 곳에서 상위 또는 하위 타입의 예외를 잡아 특정한 처리를 해줄 수 있다.
DataAccessException을 찾아보다보면, 계층화가 잘되어있다고 항상 설명이 되어있다. 그렇다면 예외의 계층화는 어떤 이점이 있을까?
내가 생각하는 장점은 다음과 같다.
하위 타입의 예외부터 처리할 수 있다. 더 큰 범위인 상위 타입의 예외를 잡기 전에 하위 타입에 대한 특정 처리를 해줄 수가 있다.
계층화가 잘되어 있을수록 이러한 예외처리 흐름을 제어하는게 쉽다고 생각한다.
공부를 하는데 공부할 것이 더 늘어난다..
처음부터 욕심부리지 말고 천천히 하나하나 씩 안으로 들어가자!
잘못된 정보가 있으면 댓글로 남겨주시면 감사하겠습니다..!
출처
1. https://docs.spring.io/spring-framework/docs/current/reference/html/web.html#mvc-controller
2. https://docs.spring.io/spring-framework/docs/3.0.0.M3/reference/html/ch16s11.html
3. https://docs.spring.io/spring-framework/docs/3.0.0.RC2/reference/html/ch03s10.html
6. https://docs.spring.io/spring-framework/docs/4.0.x/spring-framework-reference/html/dao.html
7. http://www.h2database.com/javadoc/org/h2/jdbc/JdbcSQLException.html
스프링을 공부하다보면 무조건 등장하는 어노테이션이다.
내가 현재 알고있는 지식은 @Controller, @Service, @Repository 모두 @Component라는 어노테이션을 포함하고 있기 때문에 컴포넌트 스캔 대상이되어 빈으로 등록된다는 것이다.
그런데, 이런 의문점이 생겼다.
모두 @Component 어노테이션을 포함하는데, 굳이 구분하는 이유가 무엇일까?
각각의 특징이 따로 있는 것일까?
모두 스프링 컨테이너가 관리하는 빈의 등록되기 위해서 위와 같은 어노테이션을 사용했다면, @Component만 쓰면 되었을텐데 왜 나누어 놓은 것일까? 그 이유가 분명히 있을 터..! 이러한 의문점에서 시작하였다.
@Controller
첫 번째로 Intellij안에서 @Controller 어노테이션에 들어가 봤다.
주석에 간단한 설명이 되어 있는데, @Component의 특수한 역할을 한다고 되어 있는데 특수한 역할이 뭘까..?
또한, @RequestMapping을 기반으로한 handler methods와 함께 사용된다고 나와있다... 흠..?
이것만으로는 충족이 안된다. @Component와의 근본적인 차이점을 찾아야한다.
두 번째로 Spring documents를 뒤져보았다.
공식 문서를 보다가 다음과 같은 문장을 보았다.
The basic purpose of the @Controller annotation is to act as a stereotype for the annotated class, indicating its role. The dispatcher will scan such annotated classes for mapped methods, detecting @RequestMapping annotations (see the next section).
요악해보자면 dispatcher가 @Controller 어노테이션이 달린 클래스들을 스캔하여 @RequestMapping 어노테이션이 달린 methods를 찾는다.
아마도 여기서 얘기하는 dispatcher는 내가 어렴풋이 알고 있는 dispatcherServlet을 말하는 것 같다.
내가 생각하기로는 DispatcherServlet으로 들어온 요청에 url에 맞는 method를 호출해야하는데, 그렇다면 어떠한 method들이 요청을 처리할 수 있는 method들인지 알아야한다. 이렇게 요청을 처리할 수 있는 method는 @RequestMapping 어노테이션이 달려있는 method일 것이다. 모든 곳을 뒤져볼 수는 없으니, @Controller 어노테이션이 달린 클래스 안의 method들만 detect하여 요청을 처리할 수 있는 method들을 가져오는 것 같다.
자세한 내용을 알기 위해서는 DispatcherServlet이 요청을 매핑하는 과정을 알아야할 것 같다. 너무 들어가면 한도 끝도 없으니..
일단 스프링 기술부채에 기록해둬야겠다..! ㅎㅎ
@Service
이제 알아볼 것은 @Service이다. Presentation Layer와 Persistence Layer사이에 존재하는 Layer에 붙는 어노테이션이다.
Presentation Layer에서 요청 받은 작업을 실질적으로 행하는 곳으로, 일련의 비지니스 로직을 실행한다.
위와 마찬가지로 Intellij에서 @Service에 들어가보자!
"Business Service Facade" ?? 비지니스 서비스라는 것을 알려주기 위함인가?
딱히 @Service를 붙인다고 해서 @Component와 차이점을 설명해주고 있지는 않다.
두 번째로, 공식 문서를 뒤져보자 !
It is also possible that @Repository, @Service, and @Controller may carry additional semantics in future releases of the Spring Framework. Thus, if you are choosing between using @Component or @Service for your service layer, @Service is clearly the better choice. Similarly, as stated above, @Repository is already supported as a marker for automatic exception translation in your persistence layer.
요약해보자면, 서비스 레이어에서 @Component, @Service 중 선택을 해야한다면, @Service를 선택하는게 명백히 최고의 선택이라는 것이다. 왜냐하면, 언젠가 @Service 어노테이션에 추가적인 의미, 즉 기능을 부여할 수도 있기 때문이라고 한다. 마치 @Repository가 이미 @Component와는 다르게 persistence layer에서 자동으로 예외를 변환시키는 작업을 포함하고 있는 것처럼 말이다.
생각을 정리하면, @Service 어노테이션을 붙인다고 해서 @Component와는 차이가 없지만, 미래에 추가적인 기능이 생길 수도 있으므로, 서비스 레이어서는 @Service를 붙이라는 것이다. 일리가 있는 말이군요... 기능상의 차이는 아직까지는 없다!!
@Repository
Database와 interaction을 하며 Persistence layer에 붙이는 어노테이션이다.
과연 컴포넌트스캔 대상이되어 자동으로 빈으로 등록되는 일을 제외하고 어떤 작업을 추가로 해줄까..?
아까 @Service 어노테이션을 찾아보다 힌트를 얻었다. 예외변환 작업을 해준다는데... 일단 Intellij에서 어노테이션을 까보자!
이 글과는 관련이 없지만, DAO와 DDD-style의 repository의 차이점을 이해해야 한다고 써져있다.
그러고보니, 미션을 진행할 때 DAO 클래스위에 @Repository 어노테이션을 달아줬었는데... DAO와 Repository의 차이가 뭘까?
이것도 기술부채에 추가해야겠다 !
주석을 읽어보면 결국 예외 변환을 시켜준다는 얘기인것 같다. PersistenceExceptionTranslationPostProcessor와 결합하여 Spring의 DataAccessException으로 변환해준다고 나와있다.
PersistenceExceptionTranslationPostProcessor에 대한 문서에 아래와 같이 나와있다.
Bean post-processor that automatically applies persistence exception translation to any bean marked with Spring's @Repository annotation, adding a corresponding PersistenceExceptionTranslationAdvisor to the exposed proxy (either an existing AOP proxy or a newly generated proxy that implements all of the target's interfaces).
Translates native resource exceptions to Spring's DataAccessException hierarchy.
Autodetects beans that implement the PersistenceExceptionTranslator interface, which are subsequently asked to translate candidate exceptions.
요약하자면, @Repository 어노테이션이 붙어있는 어떠한 빈이면, Bean post-processor가 예외변환을 해준다.
즉, native한 리소스 예외를 스프링이 제공하는 DataAccessException 계층 구조로 변환해준다는 것이다.
공식문서를 더 찾아보면 아래와 같은 얘기가 나온다.
Spring provides a convenient translation from technology-specific exceptions like SQLException to its own exception class hierarchy with the DataAccessException as the root exception. These exceptions wrap the original exception so there is never any risk that one might lose any information as to what might have gone wrong.
스프링은 SQLExeption과 같은 기술구체적인 예외를 자신의 예외클래스 계층구조인 DataAccessException으로의 편리한 변환을 제공한다고 한다. 이러한 예외는 원본의 예외를 감싸고 있으며, 무엇이 잘못되어서 예외가 발생한건지에 대한 어떠한 정보도 잃어버릴 위험이 없다고 한다.
그렇다면 왜 예외를 변환하는 것일까? 예외를 변환하면 이점이 무엇일까?
내 생각은 다음과 같다.
1. 특정 데이터베이스에 의존적인 예외를 wrapping하여 공통적인 예외처리를 할 수 있다.
H2 데이터베이스를 사용했을 때, JdbcSqlException이 발생할 수 있다. 이런 예외가 발생할 수 있기에 서비스 레이어에서는 try-catch구문을 사용하여 해당예외를 잡을 수 있다. 하지만, 중간에 데이터베이스가 바뀐다면 ?
JdbcSqlException은 org.h2.jdbc.JdbcSqlException인 H2 데이터베이스만의 예외이다. 그러므로 데이터베이스가 바뀐다면 서비스 레이어안의 예외를 잡는 부분 또한 영향을 받을 수 있다.
그렇기에 예외를 DataAccessException이라는 공통적인 예외로 변환시켜 던지면, 특정 데이터베이스에 의존적인 예외를 잡지 않아도 된다는 이점이 있는 것 같다. 즉, 추상화된 예외로 서비스 계층에서 잡을 수 있다!
2. 계층화된 구조로 원하는 곳에서 상위 또는 하위 타입의 예외를 잡아 특정한 처리를 해줄 수 있다.
DataAccessException을 찾아보다보면, 계층화가 잘되어있다고 항상 설명이 되어있다. 그렇다면 예외의 계층화는 어떤 이점이 있을까?
내가 생각하는 장점은 다음과 같다.
하위 타입의 예외부터 처리할 수 있다. 더 큰 범위인 상위 타입의 예외를 잡기 전에 하위 타입에 대한 특정 처리를 해줄 수가 있다.
계층화가 잘되어 있을수록 이러한 예외처리 흐름을 제어하는게 쉽다고 생각한다.
공부를 하는데 공부할 것이 더 늘어난다..
처음부터 욕심부리지 말고 천천히 하나하나 씩 안으로 들어가자!
잘못된 정보가 있으면 댓글로 남겨주시면 감사하겠습니다..!
출처
1. https://docs.spring.io/spring-framework/docs/current/reference/html/web.html#mvc-controller
2. https://docs.spring.io/spring-framework/docs/3.0.0.M3/reference/html/ch16s11.html
3. https://docs.spring.io/spring-framework/docs/3.0.0.RC2/reference/html/ch03s10.html
6. https://docs.spring.io/spring-framework/docs/4.0.x/spring-framework-reference/html/dao.html
7. http://www.h2database.com/javadoc/org/h2/jdbc/JdbcSQLException.html